Mohlo by vás také zajímat
Dochází rezervy VZP? Hoďte to na další vládu
Kryštof Míšek 20. února 2025Příští vláda se již bude potýkat s negativním demografickým vývojem, proto lze očekávat další propady hospodaření veřejných zdravotních pojišťoven. A…
Konec rutinní práce? Agenti AI už dnes mění fungování firem
5. února 2025Místo pasivního zpracování informací, bude AI autonomně rozhodovat, plánovat a jednat bez přímého lidského dohledu. Tento posun otevírá nové možnosti…
Akciový výhled podle Saxo Bank: Cesta pro investory bude spíše drsnější
Charu Chanana 21. ledna 2025Investorská portfolia se v minulých měsících do značné míry soustředila na velká jména technologických firem, případně na další americké akcie…
- ČLÁNEK
Lhali včera a lžou dnes. Budou lhát i zítra? Kde je pravda o statistikách nákazy covidem-19?
Na jaře, kdy začala pandemie koronaviru, bylo reprodukční číslo jedním ze základních údajů, podle nichž vláda měřila úspěšnost svých opatření. Ústav zdravotnických informací a statistik jej zveřejňuje pravidelně. Podle Radka Škody jsou však výpočty ÚZIS nepřesné, což dokládá grafy a vlastními výpočty.

Prof. RNDr. Ladislav Dušek, ředitel ÚZIS ČR při prezentaci dat o nákaze Covid-19 v ČR. Zdroj: ÚZIS
Nakažlivost koronaviru uvádí tzv. reprodukční číslo vyjadřující počet osob, které stihne osoba s onemocněním v průměru nakazit. Jenže zatímco slyšíme, že reprodukční číslo je 1,3, tak to není pravda a celé září nebylo. Je to spíše 2, pokud ne více. Proč nás vodí za nos?
Dám na odborníky, pokud tedy nezalžou. Pokud nemluví pravdu týdny v řadě, spoléhám pak raději sám na sebe.
Když dočtete až do konce k poslednímu obrázku (klidně přeskakujte), je zde návod, jak si sám čísla úmrtí na covid spočítat. S pomocí vlastního počítače.
Lépe připraveni
Šéf Ústavu zdravotnických informací a statistik (ÚZIS) Ladislav Dušek 26. 8. na DVTV řekl: „Teď jsme na koronavirus ještě mnohem lépe připraveni, než jsme byli v březnu.“
Karma byla rychlá, do týdne koronavirus i s hlavní hygieničkou Jarmilou Rážovou chytil (což jim nepřeji). Rychle se zotavil (a to mu přeji), ale nepoučil.
Už 11. 9. přišel s prohlášením: „Celkové reprodukční číslo kalkulované pro celou populaci ČR je rovno 1,35 (95% interval spolehlivosti: 1,32–1,38). Stále jde tedy o kontrolované šíření nemoci, lineární, nikoli exponenciální.“
Panu profesoru Duškovi jsem hned napsal e-mail, že 1,35^X opravdu není přímka. Neodpověděl.
Kde se bere ta přesnost?
Navíc se mi ani nepozdával interval spolehlivosti reprodukčního čísla uváděný v rozmezí 1,32–1,38, což je hodně přesné a až příliš dobrý odhad (například Indové s více než tisíci mrtvými za den ho nemají takhle přesný).
A začal jsem pátrat, jakýže to model na ÚZIS používají. Našel jsem to poměrně rychle, je to britský SEIR model z března tohoto roku.
Pak přišla od ÚZIS nová zpráva ze 13. září, že R = 1,59 a 95% interval spolehlivosti je 1,40–1,79 (tedy širší interval při větším vzorku dat; zajímavé).
Dva dny po sobě se výpočet ani v intervalech neprotnul (1,32–1,38 se úplně míjí s 1,40–1,79), přitom situace v Česku byla stále stejná. (Mimo jiné šlo o dobu, kdy premiér Andrej Babiš slušnému Adamu Vojtěchovi nepovolil žádná opatření.)
Bylo mi hned jasné, že model je celý špatně. Model SEIR má mnoho parametrů a ty buď ÚZIS neumí nastavit, nebo je bere špatně jako konstanty (proto ten malý interval).
Ověření na starých datech, jemuž se odborně říká backtesting, zjevně asi také nedělali. Napsal jsem opět prof. Duškovi, že takhle ne. A překvapivě opět žádná odpověď.
Nefunkční hygiena
Mezitím moje dcera byla odpoledne s kamarádkou a tu druhý den diagnostikovali na covid. Kamarádka dceři hned volala, že se jí určitě ozve (pražská) hygiena. Ta se věru ozvala, ale až za deset dní. Karma tedy fungovala i na hlavní hygieničku.
Bylo jasné, že nejenže výpočtový model je špatně, ale i sběr dat a celá hygiena v Česku nefungují.
Nedalo mi to a začal jsem si detailněji prohlížet „publikovaná“ česká data na stránkách Ministerstva zdravotnictví.
Zároveň jsem zaslal ÚZIS požadavek, aby mi pro akademické účely byly poskytnuty aktuální sety dat. Abych si je mohl analyzovat. Jako státní instituce by samozřejmě měli, ale data mi dodnes neposkytli.
Pohled na data
Pojďme se podívat na data, je to věru zlé:
- Celý graf je mimo mrtvých špatně: nestíháme ani testovat, ani trasovat, realita je N-krát větší. Netušíme, kolik lidí bylo nemocných, takže neznáme ani uzdravené.
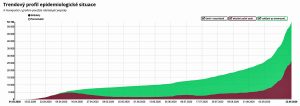
2. Nestíháme testovat. Barvičky jsou pěkné, ale z naprosto špatných dat.
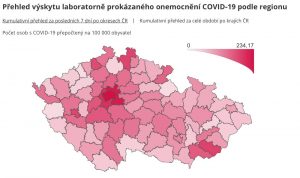
3. Opět nestíháme testovat, zahrnutí N testů stejné osoby dělá z tohoto grafu nepoužitelný zdroj.

4. Další nepoužitelný graf. Hygiena netrasuje, hodně lidí (hlavně bez příznaků) se nakazí a uzdraví, aniž by se vůbec kdy testovalo.
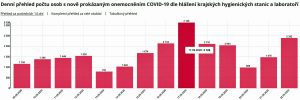
5. Opět nepoužitelné. Hygiena nefunguje. Těší mě, že tam jsem zahrnut za placený test za 2 500 Kč, abych mohl vyjet do Slovinska… Ale kolik takových zbytečných testů zde máme zahrnuto?

6. Podíl dvou špatných čísel je co? Opět špatné číslo.

7. Ale konec dobrý, všechno dobré. Zde konečně přicházejí použitelná data:
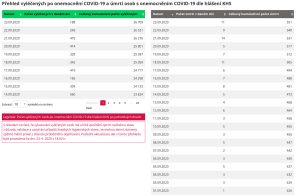
Bohužel nemám na mysli počty vyléčených (protože jsme neznali ani nakažené, o některých vyléčených se tak nikdy nedozvíme). Jsou to počty úmrtí, ty máme správně. Sice se hodnoty za poslední cca dva dny aktualizují a upřesňují, ale mrtví jsou naše datová jistota.
Jediný seriózní zdroj dat
Takže vezmeme počet mrtvých od 1. 9. do 21. 9. po dni (22. a 23. budou ještě pár dní růst, jak některé nemocnice pomalu posílají data). A šup s nimi do výpočtu:
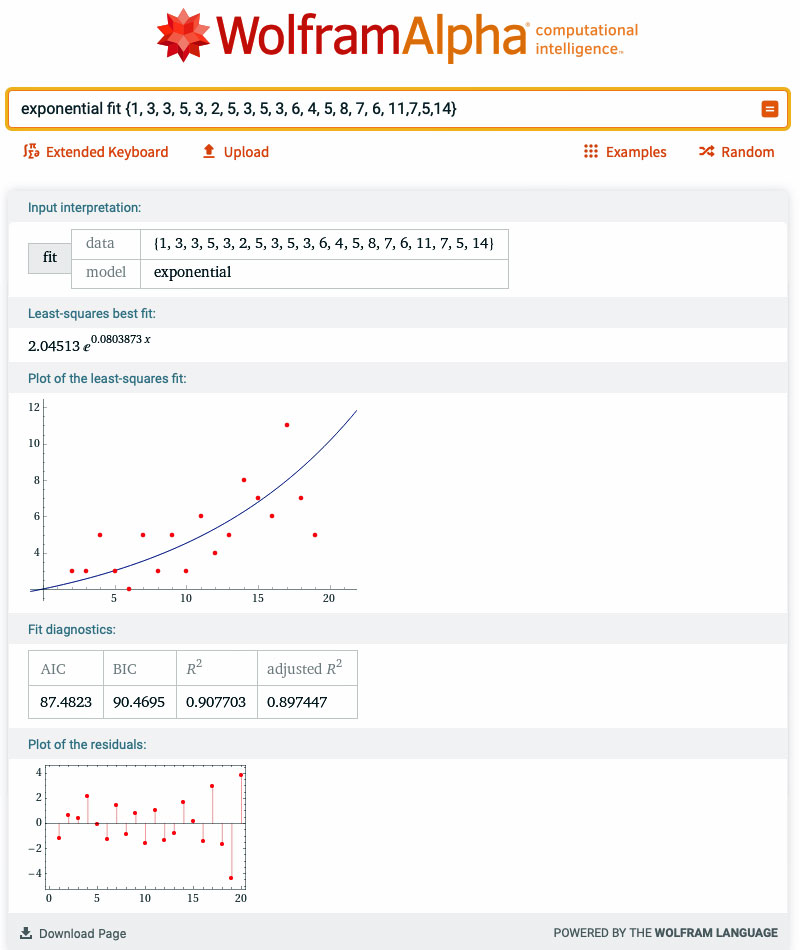
Máme pěkně nafitovanou exponenciálu. Pokud budeme chtít počet mrtvých třeba na konci září, dáme do modelu extrapolovaný počet dní (30) a vyjde nám 23 mrtvých za den:
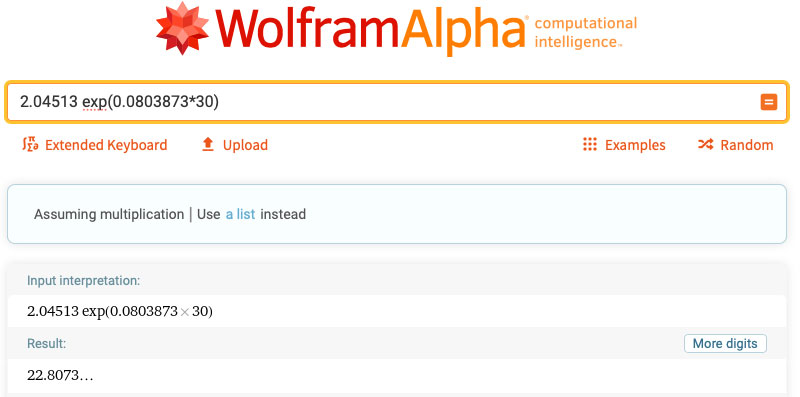
Jediný háček tu je, že musíte vzít data z období, kdy se neměnily restrikce (což v budoucnu doufejme bude). Vaše snaha při výpočtu je, aby ve „Fit diagnostics“ bylo AIC a BIC co nejmenší a R2 (pozor, není to reprodukční číslo) co největší.
Pokud bychom chtěli reprodukční číslo R, musíme zvolit při přepočtení exponentu inkubační dobu a dobu trvání nemoci. Britové volili 6,4 a 3 nebo 7. Ale to bylo v březnu, ÚZIS určitě v září najde lepší data, když mi je nemůže poslat…
Pozn. autora: V pátek 25.9.2020 v 11:00 mi ÚZIS přes dr. Gregora zpřístupnil data.
Dusek a uzis nejsou statisici. Jsou to biologove. Jo jo povinnou maturitu z matiky!!
No, i kdyby to bylo za týden 23 mrtvol denně, tak přeci data má UZIS a muže klidně zveřejnit něco jiného. Do voleb je AB zadani jasné: žádné špatne zprávy!!
Pokud to bude 23/den na konci zari, tak mozna jeste OK. Ale konec rijna vychazi dle tohoto modelu, ze bude mrtvych 250/den…
Mrtví důchodci přeci nejsou pro ekonomiku špatní: pokud jim Andrej dal 5000Kč, aby za týden volili ANO, tak pak stačí, aby jich pár tisíc po volbách umřelo a na důchodech ve výsledku stát ušetří. Andrej peníze počítat vždy uměl.
Právě teď (pátek 25.9.2020 v 11:00) mi ÚZIS přes dr. Gregora zpřístupnil data; děkuji 🙂
Já bych se uklidnil a sdělil čtenářům podle pravdy i to, že epidemiologická data jsou děravá po celé EU, ale navíc že ne každý stát měl štěstí na MUDr. Julínka s Ing. Kalouskem, kteří okrájeli početní stavy a dokonce připustili pokles kvalifikace pracovníků hygieny.
Epidemiologie holt nemá žádné dlouhé časové řady jako meteorologové.. proto vám výsledky přijdou jiné a méně přesné (ovšem doufejme, že správné) než vaše čísla tvrdá technická.
Takhle to dopadne, když se matematický teoretik pustí do analýzy na základě velmi pochybných čísel. Vyjde mu z toho nesmysl, ale vypadá to velice vědecky a seriózně.
Ví pan Škoda, že většina úmrtí ve statistice nejsou následkem COVID, protože se fixluje s daty? Ví pan Škoda, že velká část, ne-li dokonce většina „hospitalizovaných“ jsou uzdravení pacienti, kteří nemají vlastní bydliště (cizinci z hotelů nebo obyvatelé domovů pro seniory), kteří se nemohou vrátit, protože mají pozitivní testy? Ví pan Škoda, že procento pozitivních testů PCR (v podstatě false positive) se může libovolně zvyšovat nebo snižovat nastavením počtu replikací Cq? atd… Dosadit čísla do vzorečku dokáže každý blbec, ale získat skutečně pravdivá a věrohodná čísla v tomhle chaosu, kdy, mimo jiné, ovlivňují sběr dat i vyhodnocování testů politické zájmy, to by dokázala jenom dobře organizovaná rozvědka.
Tohle je už asi třetí pokus nějakého matematika dosazovat čísla do vzorečků a dělat z nich katastrofické předpovědi aniž by si ověřil alespoň základní věrohodnost vstupních dat.
Odhad pro konec mesice muj model z 21/9 predpovedel na 22,8 mrtvych; v realite jich pak 1/10 zemrelo 21. Pro nekoho spatny model, pro nekoho dobry. Ale byl to velmi jednoduchy model, ktery si kazdy v odkazu muze prepocitat jednim kliknutim. Ted pri poklesu exponencialy tak uvidi, kolik lidi se podarilo zachranit. Naprosto s Vami souhlasim, ze data testovanych, nakazenych i uzdravenych jsou hnuj na nic. Tez medii uvadene pseudo “R” nema naprosto vahu – kdyz bylo na zacatky zari 2, uzis uvadel sve presne 1,35. O tom a datech ten clanek byl…. s exponencialami u nuklearnich reaktoru/bomb pracujeme denne.